Solutions
Resources

A machine learning algorithm uses data to learn and make decisions. The algorithm develops confidence in its decisions by understanding the underlying patterns, relationships, and structures within a training dataset. The higher quality the training data is, the better the algorithm will perform. So what is training data exactly?
Training data, also referred to as a training set or learning set, is an input dataset used to train a machine learning model. These models use training data to learn and refine rules to make predictions on unseen data points. The volume of training data feeding into a model is often large, enabling algorithms to predict more accurate labels. Oftentimes, a training set consists of about 70-80% of your entire dataset. The structure of a training set consists of rows and columns, where one row is one observation, and one column is one feature. Features are also referred to as attributes, and they are extremely important to the outcome of a machine learning algorithm. For example, if we wanted to build a model that predicts the weather, some applicable features would be temperature, cloud coverage, and humidity. The values for each feature would be one observation, or row, in the dataset.
It’s common and often necessary to have some sort of human involvement when using training data for a machine learning model. The training data must fit the business and model requirements. The data needs to be scrubbed and analyzed before it can be used in the model, otherwise, the quality of the predictions will be negatively impacted. 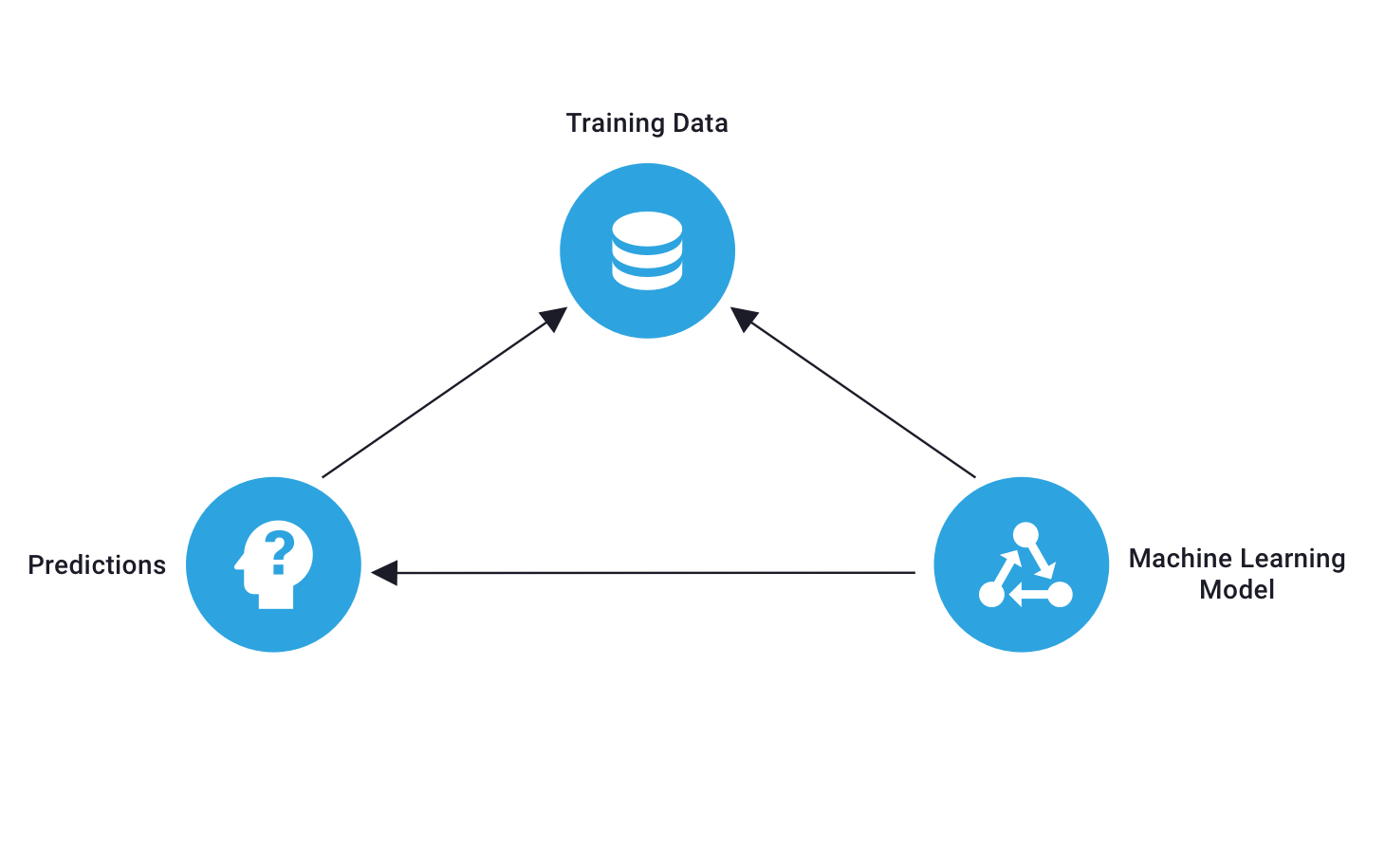
.jpeg)
Husna is a data scientist and has studied Mathematical Sciences at University of California, Santa Barbara. She also holds her master’s degree in Engineering, Data Science from University of California Riverside. She has experience in machine learning, data analytics, statistics, and big data. She enjoys technical writing when she is not working and is currently responsible for the data science-related content at TAUS.



