EPIC
Resources

The TAUS Data Summit 2018 hosted by Amazon in Seattle, brought owners and producers of language data together with the ‘power users’ and MT developers to learn from each other and to find common ground and ways to collaborate. This blog aims to give you an impression of the highlights and hot topics from this event.
Language data functions as a vital tool to drive the technology forward. It can be used in many ways, for example for leveraging translation, increasing MT performance, voice assistants as well as many natural language processing (NLP)/machine learning (ML) applications we cannot yet even envision. Based on current practices, bilingual language data comes from either translation memories (TMs) which output high-quality data produced during the translation process or from the web where data of varying formats and quality can be crawled. As an alternative, the TAUS Data Cloud, an industry-shared data repository following a reciprocal model including 30+ billion words in 2200 languages, was introduced in the use case of training and customizing MT engines. However, it turns out that a shared, reciprocal model creates mainly a one-sided market with translation buyers. When it comes to data, buyers are in abundance while providers are hard to find.
Why do people NOT share data and/or TMs?
The following potential reasons were offered by the attendees:
TAUS Director, Jaap van der Meer, made a few suggestions in his presentation to help clarify copyright on translation data. We should:
He then introduced a Data Market Model instead of an industry-shared model to address the difficulties about data sharing and copyright issues.
Based on these, the TAUS Data Roadmap was defined with the following features:
Scenario-based Applications of Cross-language Big Data
With the new neural technology wave, we see how data also make many other devices and apps become more intelligent and ambient. Chatbots for customer support, self-driving cars, smart home devices, you name it, they will not work unless we feed them with data. Data from real life and real people, how we speak and interact. In the business section of the Summit, the business opportunities around data were discussed, opened with the use case presentation by Allen Yan (GTCOM). Allen shared the evolution of GTCOM from a Multilingual Call Center in 2013 to using Big Data+AI for scientific research in 2018.
Part of the new concept of “cross-language big data” is being able to analyze multilingual algorithms. GTCOM NLP algorithm platform supports 10 types of languages and provides 51 types of external algorithm services, which is impressive when compared to Baidu or Alibaba platforms that both support Chinese only and provide fewer external algorithm services. Allen suggested that today we are facing the MT+Big data+AI combination. The goal is to build the man-machine coordination for language services. The discussions around whether machines will replace human still continue.
“From our perspective, the future lies in man and machine coordination” adds Allen. To showcase his perspective, he presented a video subtitling demo where MT does the translation and the human fixes the translation within the interface. He then showed the LanguageBox in action; a conference interpretation device that processes the speech data in real time and provides a simultaneous verbal translation in another language. The demos from Chinese into English and into Dutch were impressive, which led to some questions from the audience about the back-end arrangement of the device. Allen responded “We use SMT and NMT combined. We clean the data and use it in training of the MT. We invest 45 million USD annually in improving the domain-specific MTs.”
Data Pipeline: 3 Challenges
Emre Akkas from Globalme explained that the human learning experience is actually very similar to how machines learn, based on experiences with his own baby daughter. Babies, just like machines, collect data every day to capture all these data points, classify them to use in practice in the future. Computer scientists utilize the same method to teach computers to perform certain tasks.
Approximately how many hours of speech data do you need to train a basic ASR engine? Obviously the more the better, but around 300 hours would be a decent amount to do that. More significant than the amount of data, managing the data to enable the connection between various data points is crucial. The hardest part of this equation is the data bias, according to Emre. We all understand that people raised in different regions with different levels of ethnic diversity would behave differently. Well, the same applies to machines.
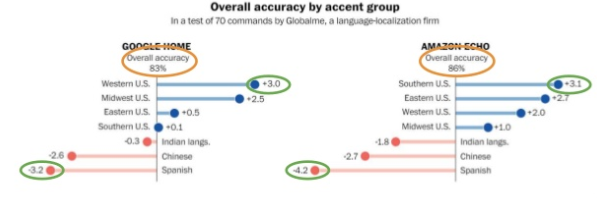 This visual shared by Emre clearly shows that the accuracy rate measured for Google Home and Amazon Echo changes based on accent groups that directly relate to ethnic background. Providing quite some food for thought, the presentation ended with a difficult question: what if, due to this, we create/train machines that are more racist than humans?
This visual shared by Emre clearly shows that the accuracy rate measured for Google Home and Amazon Echo changes based on accent groups that directly relate to ethnic background. Providing quite some food for thought, the presentation ended with a difficult question: what if, due to this, we create/train machines that are more racist than humans?
Idea Pot from the Brainstorming Session
After setting the stage for the different themes, all the data experts in the room got together in smaller groups to study the themes and come up with answers or even more questions. Here are some of the takeaways and solutions from the brainstorming session.
And the following questions and concerns were raised:

Şölen is the Head of Digital Marketing at TAUS where she leads digital growth strategies with a focus on generating compelling results via search engine optimization, effective inbound content and social media with over seven years of experience in related fields. She holds BAs in Translation Studies and Brand Communication from Istanbul University in addition to an MA in European Studies: Identity and Integration from the University of Amsterdam. After gaining experience as a transcreator for marketing content, she worked in business development for a mobile app and content marketing before joining TAUS in 2017. She believes in keeping up with modern digital trends and the power of engaging content. She also writes regularly for the TAUS Blog/Reports and manages several social media accounts she created on topics of personal interest with over 100K followers.