EPIC
Resources
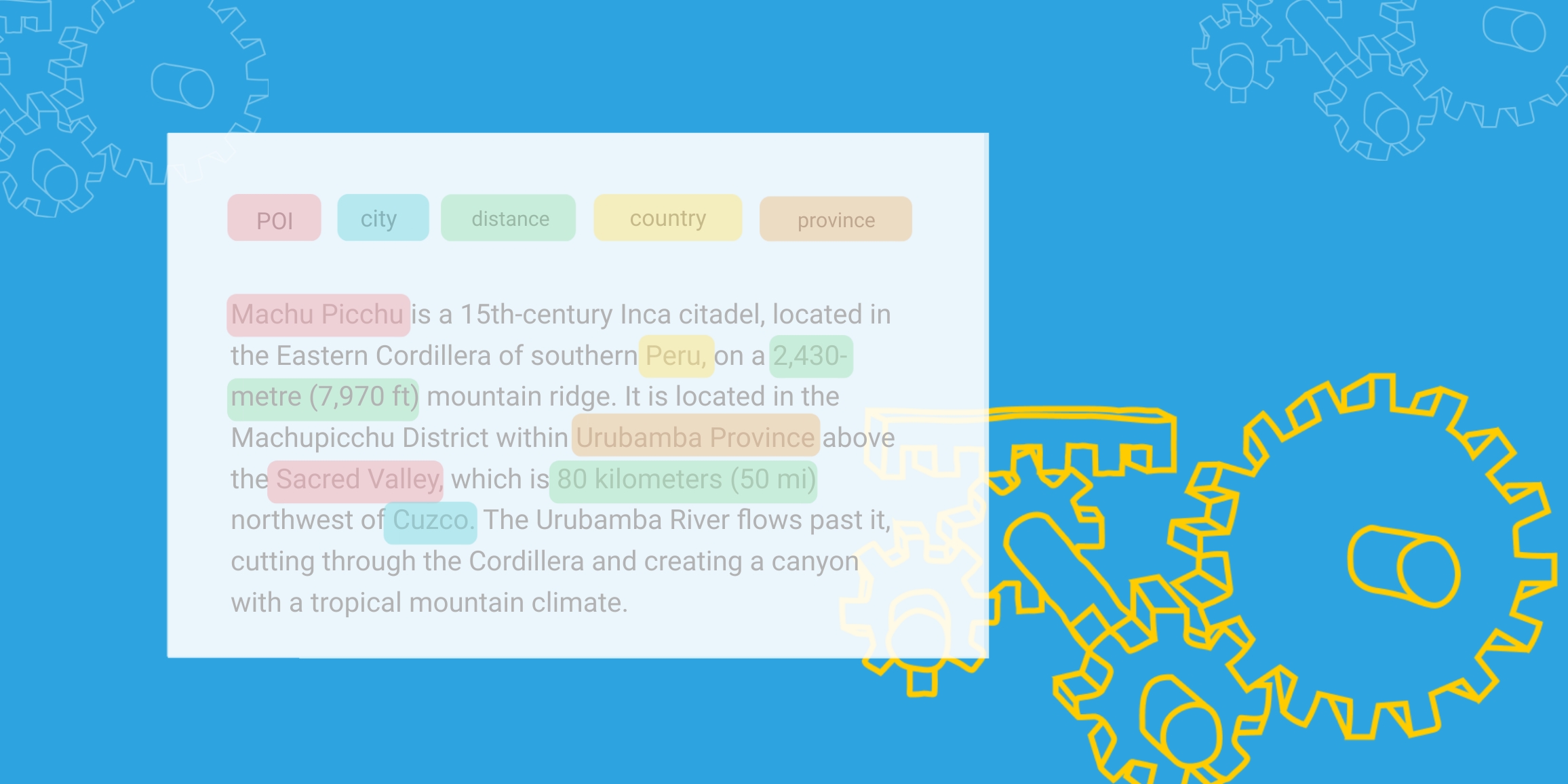
Data labeling is a key factor in artificial intelligence (AI) which enables a machine learning model to learn and output accurate predictions.
What is Data Labeling?In order for any supervised machine learning model to output accurate results, it relies on two things: an abundant amount of data and accurate labels. Data labeling is the process of assigning a group of raw data a label and it is an important aspect in the data pre-processing stage of any machine learning problem and occurs during. Labeled data can be defined as a group of data points that are assigned a target data point, or label.
An example of this can be seen in the popular Iris Data Set. This dataset describes 3 types of iris plants ( labels). The descriptive data points, or features, are sepal length, sepal width, petal length, and petal width. The output class, or label, is the type of iris plant. Thus, the labels give value to the dataset which would otherwise have little practical meaning.
Why is Data Labeling Important?
An AI model performs best when the quality of the training data is high. One major aspect that defines high-quality input data is accurate labels, making data labeling a crucial step in executing an AI model. Any machine learning model will perform better when it has learned from accurate labels in the training set.

Unlabeled data exists in many forms around us: your photos, emails, videos, satellite imagery, food labels, etc. Although this data provides a good base when seeking any sort of intelligence, it is missing labels. Labeled data is valuable because it can reflect our real-world conditions and provide us insight into decision-making. With labeled data, we can predict important conditions in the present or future, such as stock market trends, financial forecasting and, weather patterns., etc.
To make informed business decisions, it is important for any organization to have accurate labels in its predictive modeling. Measuring the accuracy of a machine learning model includes a direct comparison of the predicted labels versus the true labels. Therefore accurate labels yield an enterprise not only better predictions, but also improve a product, analytics, market insights, business decisions, and can help a business scale.
Methods of Data Labeling
Data labeling tasks often include data annotation, tagging, classification, and transcription, among others. Companies today often use a variety of techniques or services to label their data. These include the following:
Quality Assurance
Quality assurance (QA) practices are often integrated with the data labeling process. Even though it isthough is highly useful in the long run, this procedure frequently gets overlooked. Quality assurance checks help ensure that labels are being made appropriately and any errors are flagged. It provides another level of confidence in your dataset and model predictions on a larger scale. These checks are important in both manual and automated labeling techniques alike. One way to place a quality assurance check is to regularly conduct audits for data labeling tasks, which can consist of a start-to-finish examination of the data labeling process.
Data Labeling in Machine Learning
Diving deeper into the methods of data labeling for machine learning outlined above, we can categorize these tasks into two main buckets: manual data labeling and automated data labeling.
Manual Data Labeling
Data labeling that occurs internally is usually executed manually. Generally, the team performing the task has domain knowledge in order to provide more accurate labels. Because these tasks are looked over by humans, the quality of the labels is controlled and tuned according to business or modeling needs.
The downside, however, is that manual data labeling can be incredibly time-consuming and labor-intensive. Furthermore, it is more difficult to scale any AI model in this manner. As the volume of data increases, it becomes overwhelmingly impractical to continue with manual labeling tasks.
However, with the emergence of advanced platforms, such as the TAUS HLP Platform, designed to accommodate a large variety of audio/image/text-based data collection and labeling or annotation tasks, and through careful recruitment and management of a qualified global network, custom, fit-to-purpose outputs can be generated.
Automated Data Labeling Techniques
In automated data labeling techniques, either supervised or semi-supervised learning are used as a sub-task during the preprocessing stage of an AI model framework. This happens during the training dataset preparation step in a larger model architecture. Supervised learning is the process of learning labeled data points and semi-supervised learning combines both labeled and unlabeled data to classify the labels of big datasets.
Transfer learning is a technique (often used in deep learning) where a model is trained for executing one task then repurposed for a different but similar task. In our case, a pre-trained model will be used for a labeling task. This initial model would have been exposed to a similar dataset and tuned appropriately. For example, if we wish to learn labels for images of different bird species in the Amazon, we use an initial labeled (and usually smaller) dataset to pre-train our learning model. Once we learn this initial model, we transfer it to our larger unlabeled dataset to perform label predictions, as seen in the figure below. Additional human-approved datasets can be fed into the labeling model to continuously improve labeling predictions. The advantage of transfer learning for data labeling is that it is fast and efficient when we are working with big datasets. The downfall is that there is room for error and the initial pre-trained model will likely perform better than the learned model.
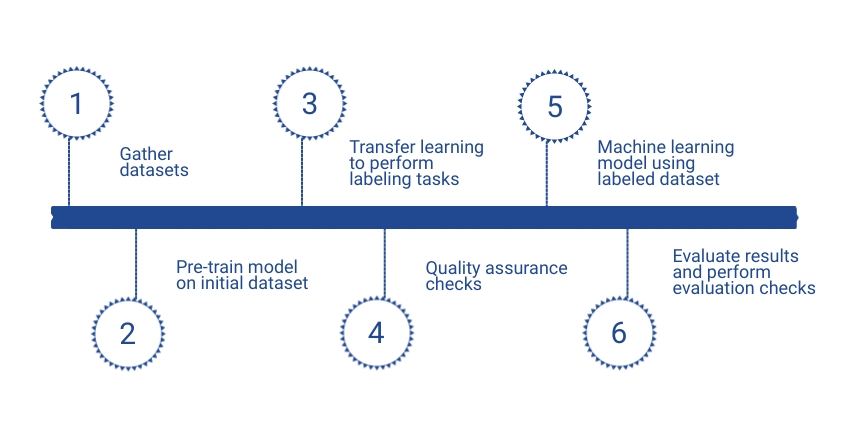 Other common automated data labeling techniques and applications include computer vision and natural language processing (NLP). In computer vision, in order to generate a training set, a bounding box consisting of labeled pixels enclosing an image is needed beforehand. Images can be either classified by content or quality type. This data can then be applied to a computer vision model that detects, segments, or categorizes images.
Other common automated data labeling techniques and applications include computer vision and natural language processing (NLP). In computer vision, in order to generate a training set, a bounding box consisting of labeled pixels enclosing an image is needed beforehand. Images can be either classified by content or quality type. This data can then be applied to a computer vision model that detects, segments, or categorizes images.
In natural language processing (NLP), data labeling entails tagging texts with labels beforehand. NLP classification tasks can consist of identifying text in images, sentiment, files, sounds, etc. Once these labels are generated, they can be incorporated into a training set which can then be used to either repeat the same task or be fed into a different task.
Data Labeling Review
The quality of data labels in the input data directly translates to the output of a supervised machine learning model. The more accurate the labels, the more accurate the end predictions. Data labeling is a pre-processing step for a larger learning model. Data labeling can be performed by either human evaluation tasks or automated labeling methods. In either scenario, data quality assurance checks are important in evaluating the accuracy of data labels. Valid data labels trickle through an organization’s data structure and provide value to the business.
.jpeg)
Husna is a data scientist and has studied Mathematical Sciences at University of California, Santa Barbara. She also holds her master’s degree in Engineering, Data Science from University of California Riverside. She has experience in machine learning, data analytics, statistics, and big data. She enjoys technical writing when she is not working and is currently responsible for the data science-related content at TAUS.