Resources
language data


11/03/2024
Purchase TAUS's exclusive data collection, featuring close to 7.4 billion words, covering 483 language pairs, now available at discounts exceeding 95% of the original value.

09/11/2023
Explore the crucial role of language data in training and fine-tuning LLMs and GenAI, ensuring high-quality, context-aware translations, fostering the symbiosis of human and machine in the localization sector.

19/12/2022
Domain adaptation approaches can be categorized into three categories according to the level of supervision used during the training process.

19/12/2022
Machine learning and AI applications need data in order to work. And in order to get good results and output, the cleaner the data, the better.

19/12/2022
Text Summarization can be categorized under two types: Extraction and Abstraction. With the power of AI, summarization is becoming more popular and accessible.


07/10/2022
Synthetic parallel data generation by back-translation as a solution for the problem of translating low-resource languages and texts from low-resource domains.


22/06/2022
The implementation of AI & ML algorithms and computation techniques are helping to improve the accuracy of recognizing speech into text

20/05/2022
It is crucial to choose the right audio transcription type between verbatim, edited, intelligent, and phonetic, to best suit your transcription project needs

 by Şölen Aslan
by Şölen Aslan03/03/2022
Natural Language Technologies are on the rise: making optimal use of NLT and its subcategories is crucial to remain up-to-date with the latest AI solutions
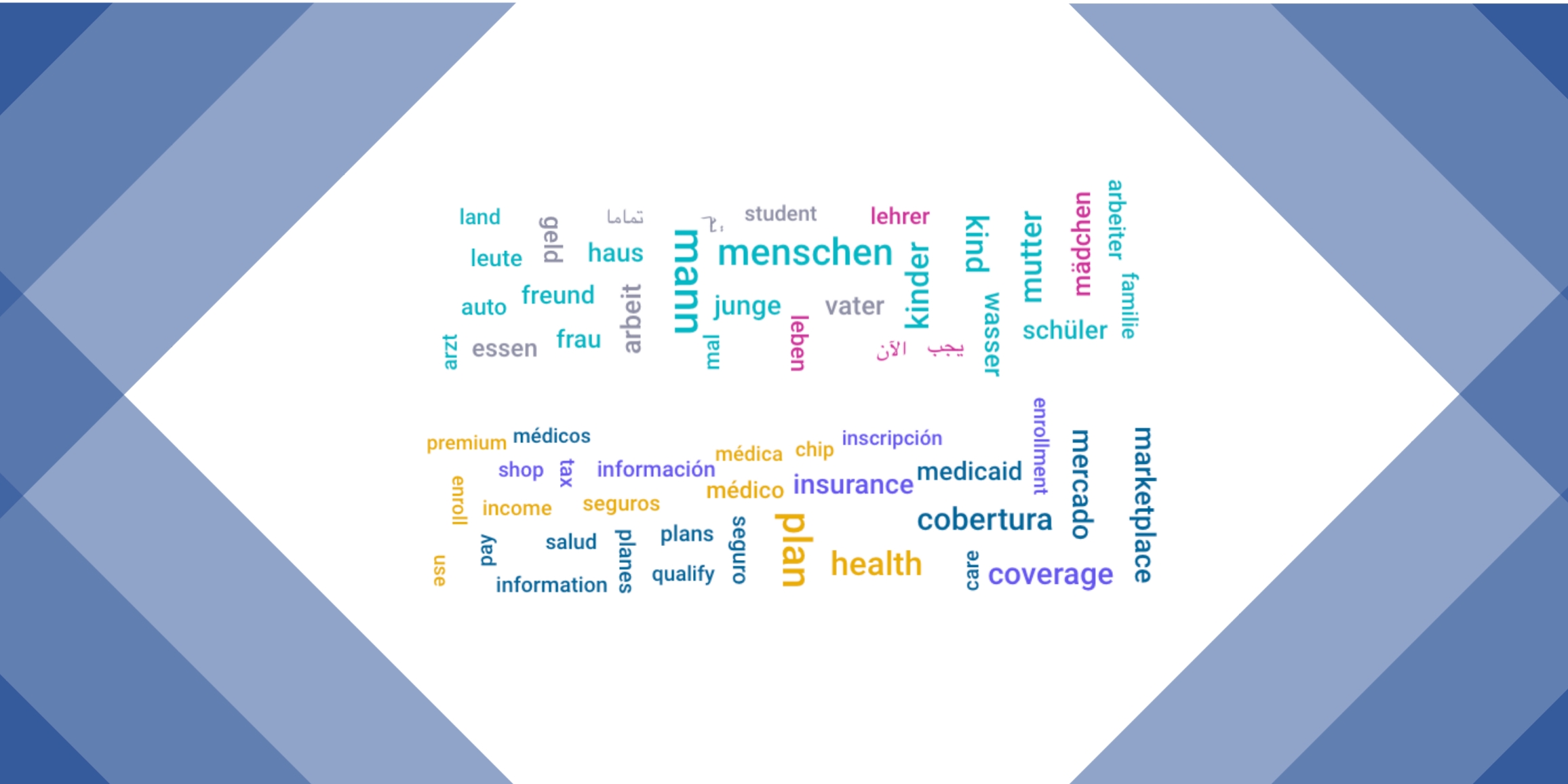

03/01/2022
What can word clouds driven by NLP tell you about your training datasets? Here is how we create word clouds on TAUS Data Marketplace.

02/12/2021
The next logical translation solution: Data Enhanced Machine Translation (DEMT)
 by Şölen Aslan
by Şölen Aslan01/12/2021
Which language data for AI trends you should expect to rise in 2022: expansion of multilingual AI data and models, more companies joining the data market, data diversity and lifelong learning machines.

.jpeg) by Husna Sayedi
by Husna Sayedi18/11/2021
A thorough overview of the paper by six Google researchers: Data Cascades in High-Stakes AI with a focus on why data-centric AI matters.
 by Husna Sayedi
by Husna Sayedi04/11/2021
Explaining what Explainable AI (XAI) entails and diving into five major XAI techniques for Natural Language Processing (NLP).
 by Husna Sayedi
by Husna Sayedi04/10/2021
A brief definition of what training data is.
 by Husna Sayedi
by Husna Sayedi04/10/2021
Reasons why training data is important for AI and ML practices.
 by Husna Sayedi
by Husna Sayedi04/10/2021
A brief introduction to types of training data including structured, unstructured, and semi-structured data.
 by Husna Sayedi
by Husna Sayedi04/10/2021
Here are some pointers on how much training data do you need to train your ML models.
 by Husna Sayedi
by Husna Sayedi04/10/2021
Data cleaning and data anonymization are very critical in training ML models. Here are the reasons why.
 by Husna Sayedi
by Husna Sayedi04/10/2021
Training data can be sourced via synthetic data generation, public datasets, data marketplaces, and crowd-sourced platforms.