Resources
.jpeg)
Husna Sayedi
Husna is a data scientist and has studied Mathematical Sciences at University of California, Santa Barbara. She also holds her master’s degree in Engineering, Data Science from University of California Riverside. She has experience in machine learning, data analytics, statistics, and big data. She enjoys technical writing when she is not working and is currently responsible for the data science-related content at TAUS.
 by Husna Sayedi
by Husna Sayedi18/11/2021
A thorough overview of the paper by six Google researchers: Data Cascades in High-Stakes AI with a focus on why data-centric AI matters.
 by Husna Sayedi
by Husna Sayedi04/11/2021
Explaining what Explainable AI (XAI) entails and diving into five major XAI techniques for Natural Language Processing (NLP).
 by Husna Sayedi
by Husna Sayedi04/10/2021
A brief definition of what training data is.
 by Husna Sayedi
by Husna Sayedi04/10/2021
Reasons why training data is important for AI and ML practices.
 by Husna Sayedi
by Husna Sayedi04/10/2021
A brief introduction to types of training data including structured, unstructured, and semi-structured data.
 by Husna Sayedi
by Husna Sayedi04/10/2021
Here are some pointers on how much training data do you need to train your ML models.
 by Husna Sayedi
by Husna Sayedi04/10/2021
Data cleaning and data anonymization are very critical in training ML models. Here are the reasons why.
 by Husna Sayedi
by Husna Sayedi04/10/2021
Training data can be sourced via synthetic data generation, public datasets, data marketplaces, and crowd-sourced platforms.
 by Husna Sayedi
by Husna Sayedi07/09/2021
Definition and common use cases of intent recognition as an essential element of NLP.
 by Husna Sayedi
by Husna Sayedi07/06/2021
Understanding the popular subfield of NLP known as sentiment analysis in ML and AI including sentiment analysis definition, types and use cases.
 by Husna Sayedi
by Husna Sayedi01/06/2021
Data preparation techniques for your machine learning (ML) model to yield better predictive power.
 by Husna Sayedi
by Husna Sayedi29/04/2021
Overview of types of machine learning and tips on selecting the right ML model for your AI applications.
 by Husna Sayedi
by Husna Sayedi19/04/2021
What is image annotation and what are some image annotation tips you can use in your AI and ML projects?
 by Husna Sayedi
by Husna Sayedi08/04/2021
Comparing synthetic data vs organic data in machine learning (ML) for an artificial intelligence (AI) application.
 by Husna Sayedi
by Husna Sayedi29/03/2021
Three key NLP tips on how to process text data for an Artificial Intelligence (AI) application, including pre-processing, feature extraction, and model selection.
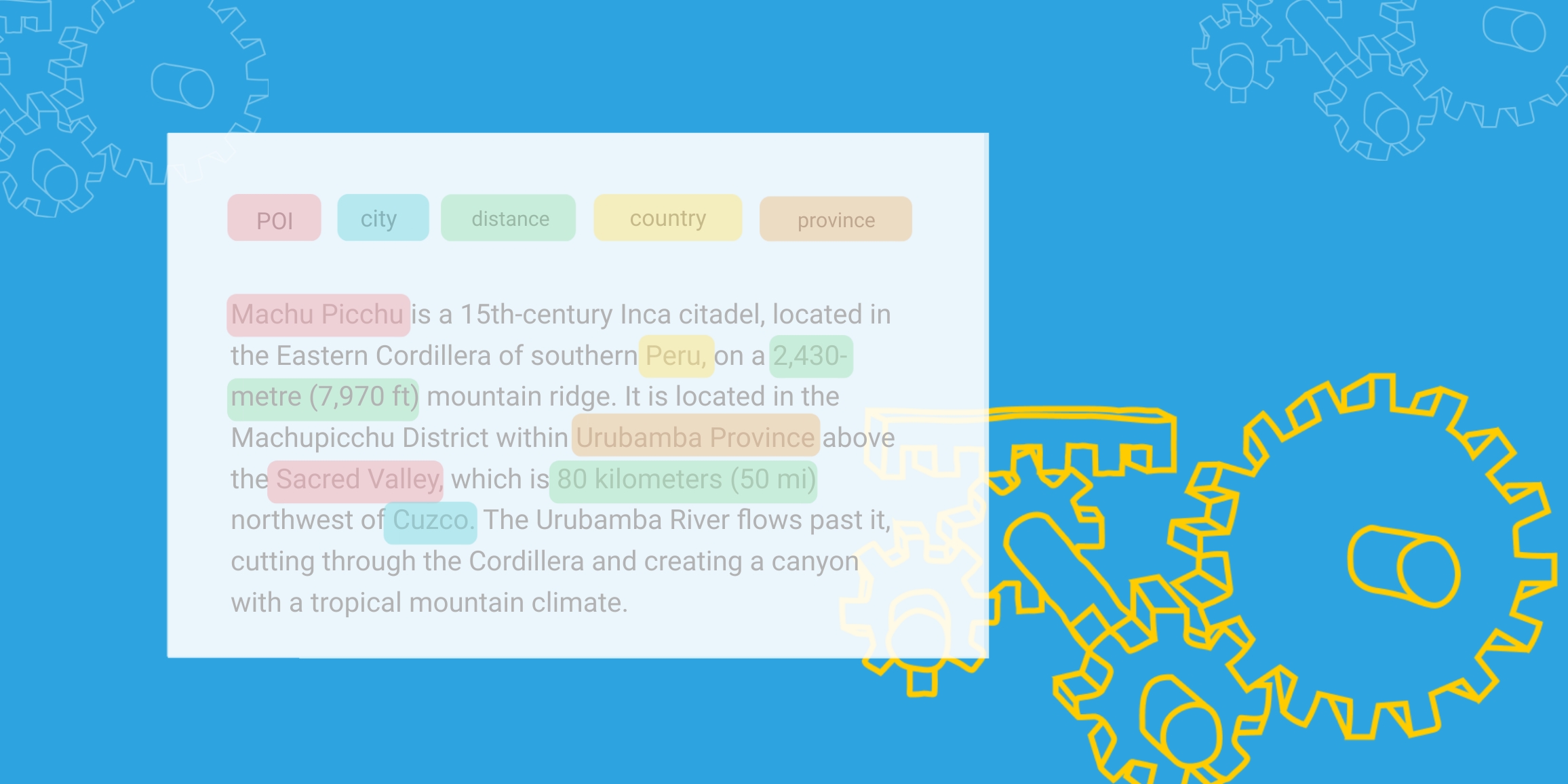 by Husna Sayedi
by Husna Sayedi17/03/2021
Data labeling is an integral step in data preparation and pre-processing for training AI and ML systems. Here is a detailed look into what it means and various data labeling techniques.
 by Husna Sayedi
by Husna Sayedi11/03/2021
How to improve the quality of your data through enhancing data integrity, data cleaning, and data modeling to advance your data science and AI (artificial intelligence) practices.