EPIC
Resources

We live in a data-driven world where much of our society’s key decision-making is based on data, ranging from governmental to industrial, commercial, and so on. Data science and AI (artificial intelligence) would not be possible without an abundant amount of data. Now that data has become mainstream in almost every industry, the quality of data has become increasingly imperative.
High-quality data is frequently talked about and sought after but what does data quality really mean? High quality data can be defined as any qualitative or quantitative data which is captured, stored, and used for its intended purposes. “Quality” data pertains to the data being accurate, complete, clean, consistent, and valid for its intended use case. There are a few key ways one could improve the overall quality of data. This includes refining and outlining data integrity, ensuring proper data sourcing, data cleaning techniques, and data storage methods.
Given the context of your data, how is the data being sourced and are these trusted sources? Once your data sourcing is validated, the next step would be to assess if your data complies with data entry standards.
Standards of data entry often depend on the business context. As a whole, this means defining a set of guidelines your data needs to fit in order to be used or stored for business purposes. These guidelines can include things like features needed, duplication management, deletion of records, formatting, and data privacy standards. Often, companies have their own unique set of data entry standards.
Once your data has been properly captured, another measure to take to improve data quality is data organization and storage, also known as data modeling. Data modeling is a process that bridges the gap between business processes and the data needed by analyzing the data requirements needed to support the business needs. This practice establishes the relationships between data elements and structures within the business model. Oftentimes, diagrams or other visual representations are used to model the flow of data within the organization. As the scale and volume of data increases, data modeling becomes more vital to ensure data consistency. The TAUS Data Marketplace is a great example of hundreds of data sources organized and stored in an efficient model, according to several differentiators including domain and language pair.
Data models within an organization have many benefits, namely improved software development, analytics, application performance, risk management, data tracking, documentation, and faster market turnarounds. When data is organized within the organization, it becomes easier to understand and thus apply any layer of analytics or modeling on top of it. Subsequently, this improves the quality of your data, data modeling yields fewer errors in the data, better documentation, and overall fewer errors across the organization.
Data quality is directly tied to data integrity. Data integrity refers to the accuracy, consistency, completeness, and reliability of data throughout its lifecycle. Data integrity is introduced during the database modeling and design phase. It is enforced through the use of standard procedures and rules consisting of various validation checks and procedures. Hence, data with high integrity indicates the quality of the data is high as well. Each organization creates these procedures independently and there is no one-size-fits-all method. There are, however, some commonplace procedures found across many enterprises. An example of a common method used across many different companies is following a software development lifecycle (SDLC), which are a set of guidelines and rules to follow standard business practices while building any application. SDLC methodologies improve data quality because it provides a scalable view of the organization both from a technological and business standpoint. It is a way for the organization to track all of their data, applications, tests, code, transactions, and so on. Furthermore, SDLC shows you exactly how the data is being used as well as any vulnerabilities or areas of improvement.
Once we have established data integrity practices and guidelines, the next step we can take to improve data quality is to clean our data. Data cleaning is a part of data integrity and an essential part of any data science and AI use case. Clean data yields better algorithms and results. Messy data containing noise will be sure to mask potentially insightful results or introduce bias in your outcomes. Hence, data cleaning is an effective measure to take to ensure data quality.
Cleaning your data can fix common errors in data such as syntax, type conversions, and duplicates. There are a variety of data cleaning techniques to utilize, but ultimately these depend on the use case and business model. Some common data cleaning techniques to implement are data normalization, standardization, anonymization, duplicate prevention, and data inspection. Data inspection practices can help identify incorrect and inconsistent data points. Data normalization will help ensure things such as case, abbreviations, and other syntax-related issues. For example, we can normalize data points such as “U.S.” and “America” to a single representative entry such as “United States.” TAUS Data Services is an example of a service that cleans, prepares, secures, finetunes, and customizes data.
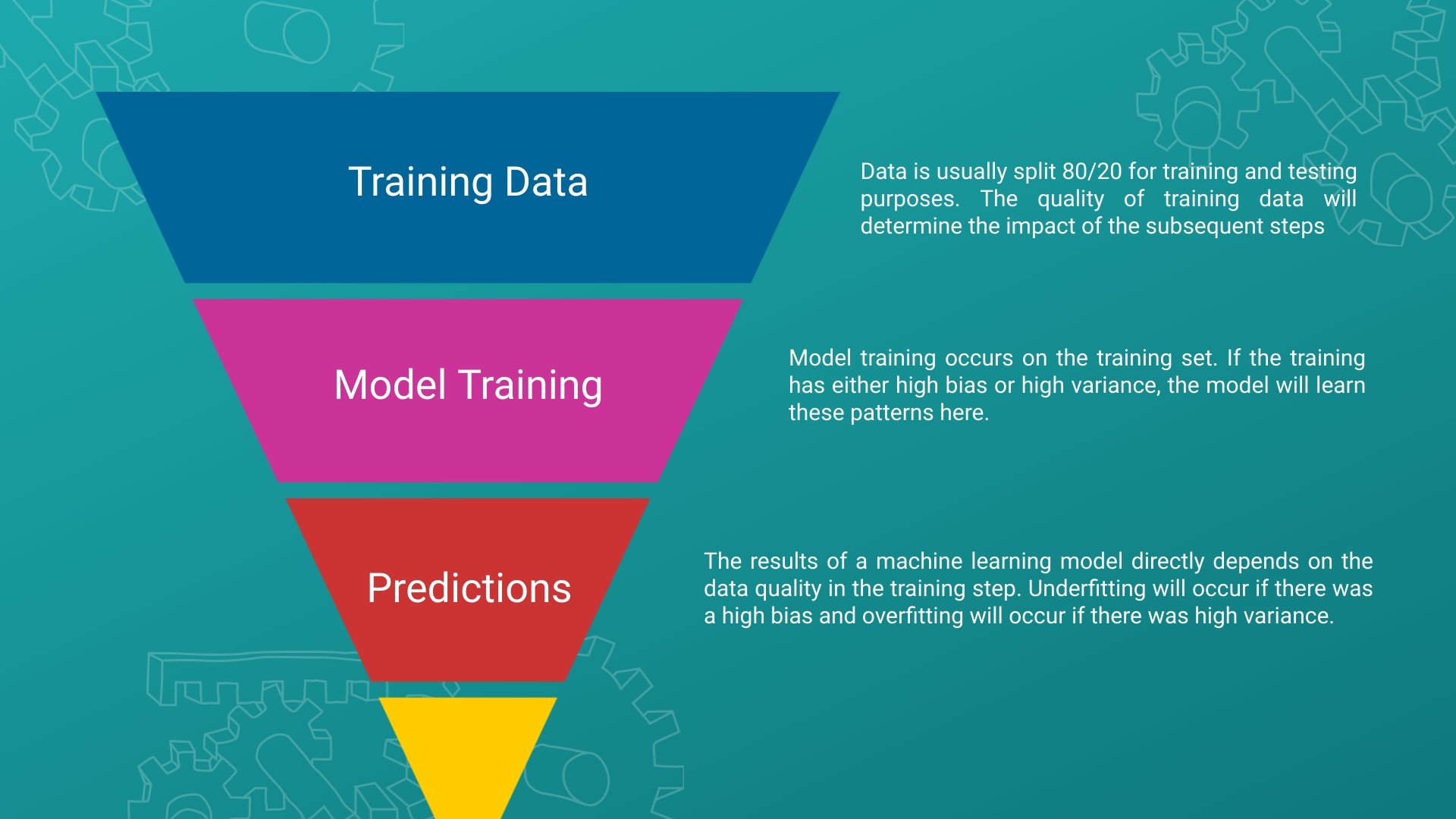
One area of AI that portrays how data quality can have a profound impact is machine learning. Machine learning is a subset of AI and it is defined as a set of methods which automates model building and decision making. Machine learning models often require training data to build intuition and perform decisions, which generally improves with more time and increased training data. It is easy to see how inconsistent, noisy, or subpar data will skew a model’s output. In some cases, this can have a drastic impact on business implications.
One way we can build intuition on our data quality in a machine learning model is by assessing the bias and variance. Underfitting occurs when the model has not sufficiently caught the underlying patterns of the data and the model has over-generalized. This means there was high bias, which indicates that there was not sufficient data for the model to train on. On the other hand, high variance occurs when the model learns noise from the training set. This leads to overfitting, where the model has over-generalized to the training data. In both scenarios, the quality of the training data plays a key role in the outcome of the model’s training phase. In this case, the factors that made the training data of low quality was either too little data or noisy data. You can improve the quality of the data here by increasing the training size and conducting proper data cleaning techniques to remove noise, as mentioned above.
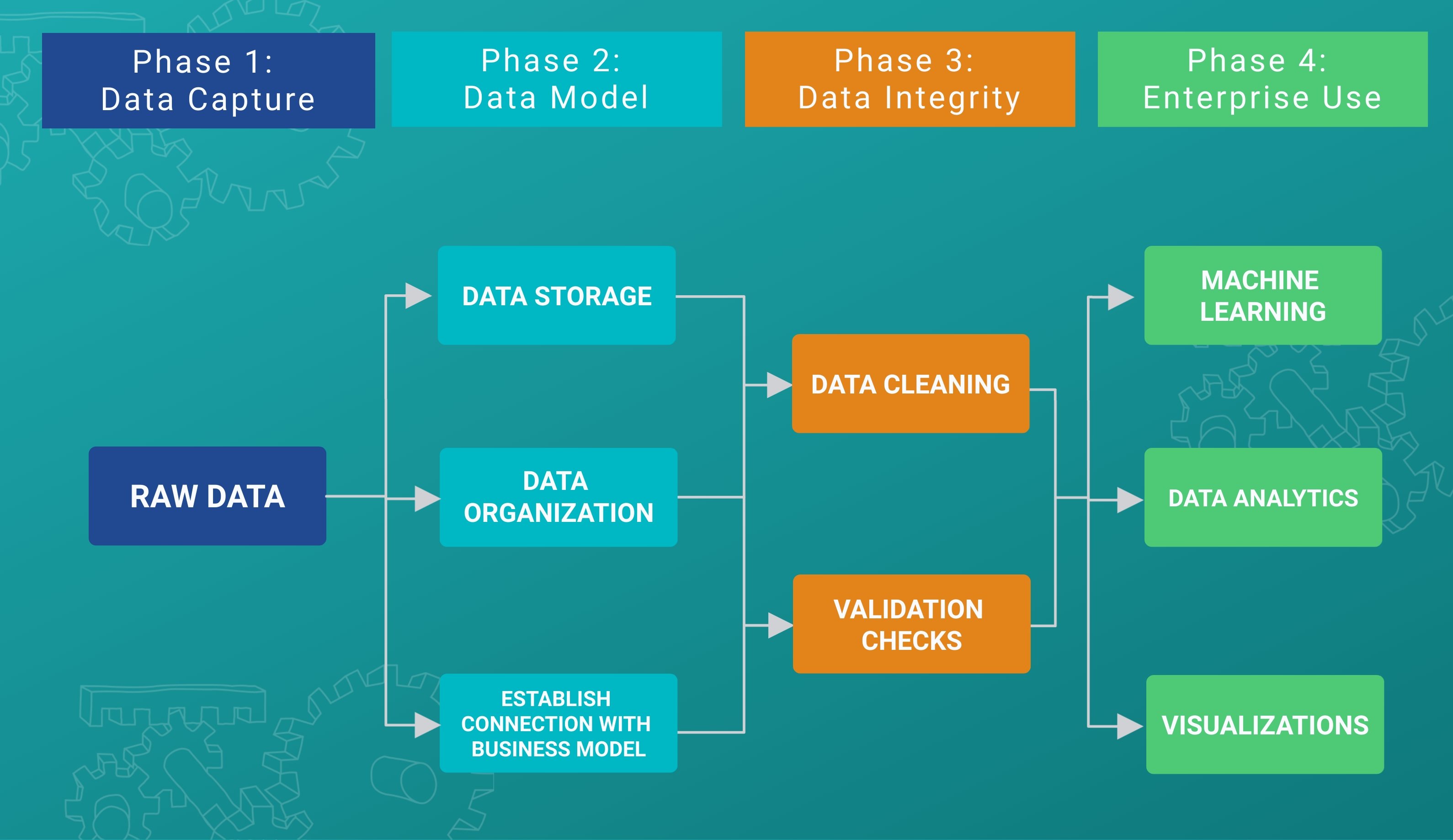
Data quality review is an essential part of any organization. The above diagram outlines the lifecycle of data and shows how data quality is improving through each phase. It is important to note, however, that organizations may structure these phases differently according to their standards and processes. One example of a real-world data platform is the Human Language Project (HLP). HLP is a micro-task-based platform where people can generate and annotate data or evaluate data quality in given domains and projects.
The more steps that are taken for data to accurately represent real-world constructs, the more trustworthy and meaningful results can be. Through proper data capture, integrity practices, and data modeling methodologies, data quality can be significantly improved.
.jpeg)
Husna is a data scientist and has studied Mathematical Sciences at University of California, Santa Barbara. She also holds her master’s degree in Engineering, Data Science from University of California Riverside. She has experience in machine learning, data analytics, statistics, and big data. She enjoys technical writing when she is not working and is currently responsible for the data science-related content at TAUS.