EPIC
Resources

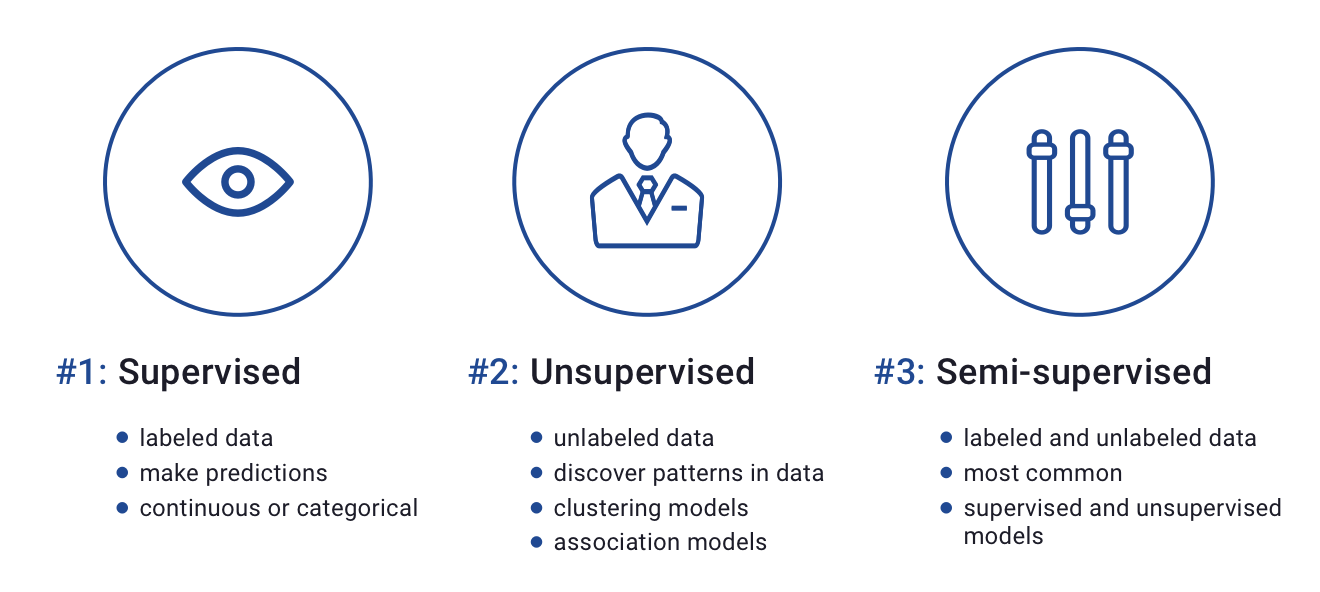
Training data is used in three primary types of machine learning: supervised, unsupervised, and semi-supervised learning. In supervised learning, the training data must be labeled. This allows the model to learn a mapping from the label to its associated features. In unsupervised learning, labels are not required in the training set. Unsupervised machine learning models look for underlying structures in the features of the training set to make generalized groupings or predictions. A semi-supervised training dataset will have a mix of both unlabeled and labeled features, used in semi-supervised learning problems.
Reinforcement learning models use learned errors and associate them with a given reward or penalty. This family of models can use either no training data and learn from experience, or use training data and learn from experience.
Within these three areas of machine learning, there are many different types of data that could be used for training, including structured, unstructured, and semi-structured data. As the names suggest, structured data are data that have clearly defined patterns and data types, where unstructured data does not. Structured data is highly organized and easily searchable, usually residing in relational databases.
Examples of structured data include sales transactions, inventory, addresses, dates, stock information, etc. Unstructured data, often living in non-relational databases, are more difficult to pinpoint and are most often categorized as qualitative data. Examples of unstructured data include audio recordings, video, tweets, social media posts, satellite imagery, text files, etc. Depending on the machine learning application, both structured and unstructured data can be used as training data.
.jpeg)
Husna is a data scientist and has studied Mathematical Sciences at University of California, Santa Barbara. She also holds her master’s degree in Engineering, Data Science from University of California Riverside. She has experience in machine learning, data analytics, statistics, and big data. She enjoys technical writing when she is not working and is currently responsible for the data science-related content at TAUS.