EPIC
Resources

Sentiment analysis is a subfield of Natural Language Processing (NLP) where the general sentiment is learned from a body of text. It is primarily used to understand customer satisfaction, social popularity, and feedback on a product from the general public through monitoring social or public data. There are different types of sentiment analyses that exist and are common in the real world.
Beyond the common binary classification task of learning either a positive or negative sentiment, fine grained sentiment analysis allows for polarity of sentiments. This type of sentiment analysis is commonly used to interpret and analyze 5-star rating systems. The following five discrete sentiments can be classified, as shown below.

Emotion detection is a type of sentiment analysis where emotions are learned, such as happiness, sadness, anger, etc. Emotion detection can be a difficult task, as people often express emotions very differently.
Aspect-based sentiment analysis is used when the sentiments of certain features or aspects are wished to learn. For example, in a review such as: “This dress fits too tight around the arms” reveals feedback on a certain aspect of a product, in this case, the fit of a dress. Lastly, multilingual sentiment analysis is the process of learning sentiment in a body of multilingual text. This task can prove to be rather difficult, and oftentimes external language models are required. A multilingual data platform known as TAUS HLP is one platform where customized community workers can leverage the multilingual data to perform sentiment analysis tasks.

Sentiment analysis is very useful for companies to understand how their user base reacts to a given product or service. Through quantifying, monitoring, and automating sentiments, gathered through reviews, ratings, social media, chats, or another feedback method, companies can quickly react to possible faulty features or services. In addition, enterprises are able to make more informed decisions quicker and more accurately.
Sentiment analysis allows for data sorting at scale. These data sources can consist of phone logs, chats, social media scrapes, reviews, ratings, support tickets, surveys, articles, documents, and more. Furthermore, sentiment analysis is done in real-time, giving organizations valuable insights on key metrics like churn or customer satisfaction rates. Lastly, companies have access to constant real-time critique, enabling a positive feedback loop and faster product iterations to address unhappy users.
So far, we have learned about the importance of the different types of sentiment analysis and how to algorithmically compute them using either rule-based, automatic, or hybrid-based approaches.
The most common use cases we see sentiment analysis applied to is on social media, customer service, and market research. Social media is a common area where sentiment analysis is used to monitor how people are perceiving and speaking of a brand or product. It also allows businesses to understand how segments of society perceive different topics, from trending topics to news events. Using this information, companies are able to react to public sentiment quickly. Furthermore, social media has become a prominent space for brand advertising and consumer feedback, such as product review videos. Thus, businesses can monitor metrics such as brand mentions and sentiments associated with each mention. Lastly, customer service has emerged as a prominent space for sentiment analysis. Using phone call logs or chat logs, businesses are able to understand how they perform with customer service and satisfaction. Using real-time data, they are able to ensure employees are following proper customer service etiquette and improve upon customer-client relations.
Sentiment analysis is possible due to NLP and other machine learning methodologies that detect a user’s tone through a body of text. Through these techniques, weighted sentiment scores are assigned to topics, words, or entities within a body of text, where predictions are then generated. Sentiment analysis algorithms generally fall into three different buckets: automatic, rule-based, and hybrid. Let’s dive deeper into each of the three different types of sentiment analysis algorithms.
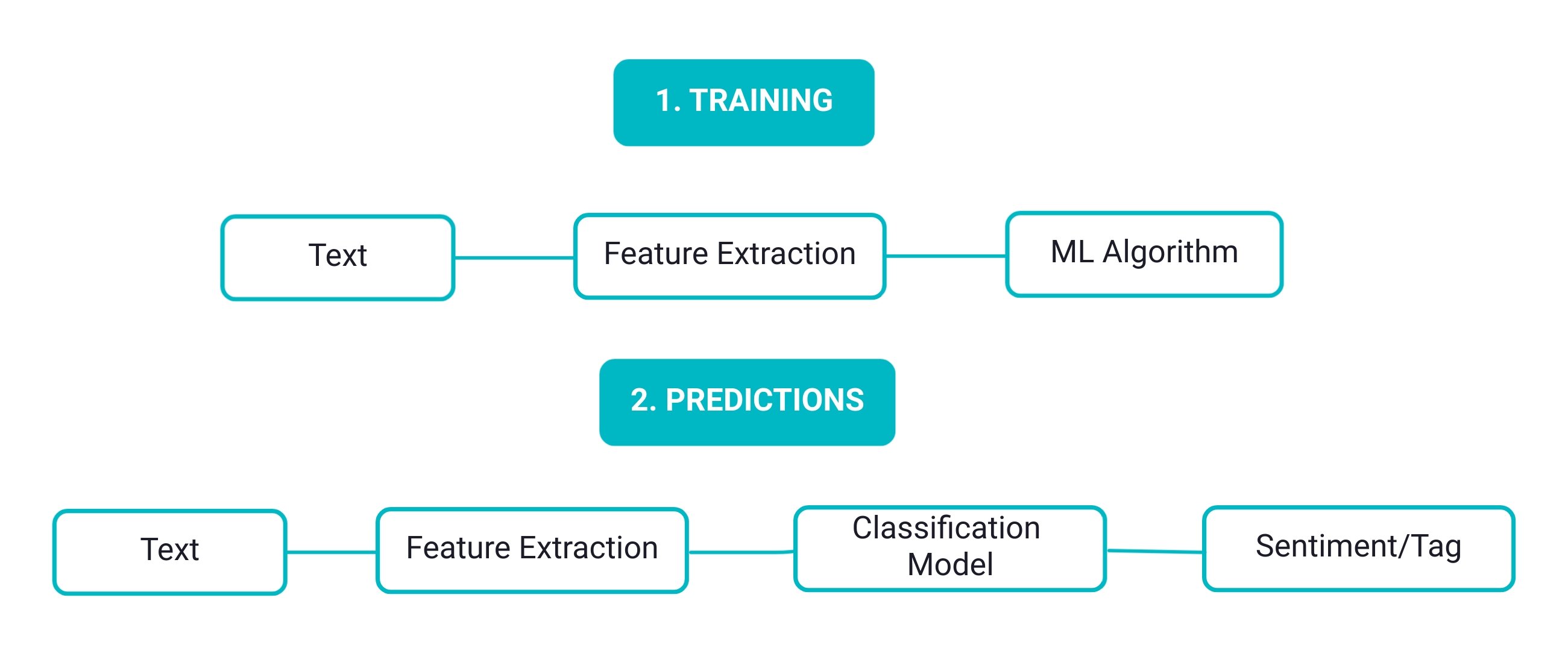
In automatic sentiment analysis algorithms, machine learning techniques are leveraged in order to learn to tag text data with different sentiments. A classification machine learning model is applied to learn whether the input text falls into a distinct set of classes of sentiments, such as positive, negative, or neutral.
The figure below displays an automatic machine learning-based sentiment analysis diagram. In the first step, input data is fed into a model where features are extracted and associated with a particular tag. The feature extraction process uses techniques such as text vectorization, bag of words, or bag-of-ngrams, word embeddings, and word frequencies. After that, the training data is classified with different sentiments (or tags) in order to attain a trained supervised model.
In the second step, predictions of classes (or tags) are generated on unseen data points, using the learned model from the training step. Common classification models that can be used are naive bayes, logistic regression, support vector machines, linear regression, and deep learning for classification problems.
 Rule-Based
Rule-Based
In rule-based sentiment analysis algorithms, the system automatically tags input data based on a set of predefined rules to identify the polarity of user sentiments. To execute these rules, NLP techniques are leveraged. These techniques include stemming, part-of-speech tagging, parsing, lexicons, and tokenization.
An example of a rule-based sentiment analysis model can be seen in the following scenario. Lists of words are applied to different sentiments. Negative words can be “horrible”, “worst”, “bad” and positive words can be “great”, “love” “amazing”, for example. Next, an input sentence is analyzed where the count of polarized words are stored. This count is then processed into buckets of different classes, such as “positive”, “negative”, or “neutral”, based on the highest count of polarized words associated with the given sentiments.
Rule-based algorithms are simple and easy to implement, however, they often overlook the complexities of text and word combinations. Rule-based or automatic algorithms can be used, depending on how advanced you want your sentiment analysis model to be.
A hybrid sentiment algorithm combines the techniques used in both rule-based and automatic sentiment analysis models. This method combines machine learning and NLP techniques to create a more complex and accurate sentiment analysis model. Although these are generally more complex to build, the outcome is that they perform more accurately than using either a rule-based or an automatic approach.
Sentiment analysis is still a developing area in artificial intelligence. Because of the complexities of how humans communicate, the field has a significant amount of space for improvement. The techniques that are used in sentiment analysis models today, however, appear promising and useful for many businesses.
Sentiment analysis for your projects can be performed by a community of analyzers that is formed based on your required specifications such as language, location, interest areas, and so on, on the TAUS HLP Platform. Contact us now to get a customized solution for your data challenges.
.jpeg)
Husna is a data scientist and has studied Mathematical Sciences at University of California, Santa Barbara. She also holds her master’s degree in Engineering, Data Science from University of California Riverside. She has experience in machine learning, data analytics, statistics, and big data. She enjoys technical writing when she is not working and is currently responsible for the data science-related content at TAUS.